This dashboard draws on every article published in The New York Times from January 2000 to the present, retrieved through the NYT Archive API and updated monthly. Errors in the API or in the function of the website could yield spurious conclusions, so users should independently verify any findings.
Identify recurring themes that the New York Times has covered disproportionately in a given geography over the past 25 years. Pick a country or U.S. state and see which subject keywords appear in coverage of that place out of proportion to comparable coverage elsewhere.
The New York Times Archive API indexes all document types published on nytimes.com — news, opinion, reviews, obituaries, and interactives — and this dashboard includes all of them.
That includes both standard articles and blog content, like those hosted at subdomains blogs.nytimes.com, dealbook.nytimes.com, and krugman.blogs.nytimes.com. Blog posts were typically much shorter (averaging 100–460 words vs. 600–900 for non-blog articles), published in higher volume, often without an author name attached. The posts from blogs (ArtsBeat, CityRoom, The Caucus, The Lede, Economix, Bits, Wheels, Fifth Down, Straight Sets, and more) peaked at nearly 56% of all indexed articles in 2009. Blog indexing then declined steadily as the NYT wound down its blog properties between 2013 and 2018; by 2019, essentially no content is published at blog subdomains.
Content from The Athletic is not available in the Archive API and is therefore absent, which is why Sports coverage appears to decline sharply after the NYT's 2022 acquisition of that publication.
Author name variants are merged when they likely refer to the same person. For example, "Jonah E. Bromwich" and "Jonah Bromwich" are treated as one byline when first and last names match and middle names are compatible. Cases where the same reporter has many articles under both a shorter and a fuller form are reconciled manually after cross-checking beats, sections, and year ranges. A separate manual override list also catches nickname / formal-first-name pairs — e.g. "Rob Mackey" and "Robert Mackey," or "Dave Itzkoff" and "David Itzkoff" — which the automatic merger cannot detect because the first names differ. Where the same reporter has been bylined under both forms, articles are credited to whichever form is overwhelmingly dominant.
Institutional bylines — The Associated Press, The Editorial Board, Reuters, and similar non-person attributions — are excluded from author rankings, because they don't represent individual reporting output.
Staff versus freelance status and role (reporter, editor, photographer, critic, etc.) are drawn from each reporter's NYT bio page where available. For reporters who lack a custom bio page, no classification is given.
The API includes a word count of each article, but has some anomalies. Interactive and multimedia pieces including data visualizations and photo essays are typically indexed with a word count of zero, even when they contain substantial reporting. Interactives make up roughly 10% of New York Times Magazine items in the API and a growing share of digital-native journalism. Word-count statistics for sections with heavy interactive output (Magazine, Upshot, Visual Investigations) and for individual authors who shifted toward multimedia formats therefore understate actual editorial output. Articles with a word count of 0 are excluded from average word count calculations per reporter and per section, on the assumption that they represent missing data rather than genuinely empty articles.
In reporter profiles, three short-form content types are tracked separately, shown in light yellow on the Articles per Year chart, and excluded from average word count: blog posts (hosted at *.blogs.nytimes.com subdomains, DealBook, and the 2014–2016 First Draft political blog); /live/ news-blog updates — short real-time entries contributed to breaking-news live streams, averaging ~500 words; and briefs — identified by the API's type_of_material="Brief" tag, used 2006–2018 for World Briefing, Arts Briefly, National Briefing, and similar short dispatches averaging ~130 words.
The NYT has also indexed podcasts inconsistently over time and across shows: some episodes are entered with a full transcript as the article body, while others appear only as short landing pages. The same show can switch policies — The Ezra Klein Show, for example, was indexed as ~400-word descriptions through 2023 and then as full transcripts beginning in 2024, while The Daily has remained short summaries throughout. Word-count trends for podcast contributors are therefore often not comparable between reporters or across years. For purposes of the reporter profiles in this dashboard, a podcast episode is identified by any of: the article's section being "Podcasts," a URL path containing /podcasts/ or /audio/, or the article's kicker matching a known NYT show title — separating true episodes from news articles that merely reference a podcast.
The NYT attaches a controlled vocabulary of keyword tags to each article it publishes, distinguishing between several types. Subjects are thematic topics (Immigration, Climate Change, Basketball (College)). Locations are geographic places (Boston (Mass), Syria) and underpin the dashboard's state- and country-level coverage views. People (e.g. Trump, Donald J) and organizations (e.g. Harvard University) are tagged separately on each article.
On this dashboard, subject tags drive the Beats tab — where you can search for any topic and see which reporters cover it disproportionately — and the recurring-themes lists in the States and World tabs. A subject is classified as a reporter's beat when she covers it at least twice as frequently (as a share of her overall coverage) as the paper as a whole, with a minimum of two articles on it; authors with few articles, or few articles carrying subject tags, may have no beats listed. People and organizations are surfaced separately on the Newsmakers tab, where you can compare coverage of any tagged individual or institution over time. Because beats and state/country recurring themes are restricted to the subject vocabulary, named entities — Harvard, Trump, the Yankees, Cambridge — never enter those analyses; they live exclusively under Newsmakers.
The NYT has renamed, merged, and discontinued sections over the years. To preserve thematic continuity, this dashboard applies the following merges:
Technical categories, product sections, branded-content labels, and small stubs — newsletter and podcast aggregators, discontinued apps, TV tie-ins, blogs without a clear section home — are excluded entirely from the Sections tab. This includes "Archives" (predominantly paid death notices), "Booming" (a 2012–2014 baby-boomer lifestyle blog), "UrbanEye" (a NYC events newsletter), and "Guide" (a going-out listings service).
Daily New York / New Jersey / Connecticut lottery-numbers entries — roughly 3,500 short standalone records published 2002–2015 with all three state geocodes attached — are excluded from every section's totals. They are surfaced separately in the Features panel. Their original section assignment was usually "New York" or "Today's Paper"; including them inflated those sections by hundreds of articles a year through 2014 and made historical comparisons misleading. Articles in other sections that happen to be about lotteries (feature stories, business coverage, briefings) are unaffected and remain in their assigned section.
Authors are assigned a primary section based on where they have published the most articles over their full career in the dataset; this is used to sort and filter the Reporters table. Author profiles also list every section in which the author has published, reflecting the full range of their work. Primary section is a rough proxy for desk assignment and may be inaccurate for reporters whose focus shifts across years.
Analysis of national coverage draws from articles in the "U.S." section and the "New York" section. Many articles in the latter section lack geographic tags, however, and are not included in the analysis. Locations internal to states (e.g., "Chicago") are mapped to their parent states. The five U.S. territories — Puerto Rico, Guam, the U.S. Virgin Islands, the Northern Mariana Islands, and American Samoa — are surfaced in a separate group beneath the 50 states and D.C. in the States table, drawing from the same U.S./New York-section pool. They are excluded from the state map's color quintiles (only the 50 states have map polygons) so a territory's coverage volume can't skew the state scale. Puerto Rico also appears as a standalone entry in the World tab, drawing on a different article pool — the small set of World-section pieces that carry its geographic tag — so the two views surface different aspects of NYT coverage.
The daily NY/NJ/CT lottery-numbers entries described in the Sections note above are also excluded from per-state article totals and from the recurring-topic scoring. They had been the dominant "Lotteries" subject hit in all three states' coverage and accounted for a large share of New York and Connecticut's pre-2015 article counts; they belong with the Features panel, not the per-state coverage view.
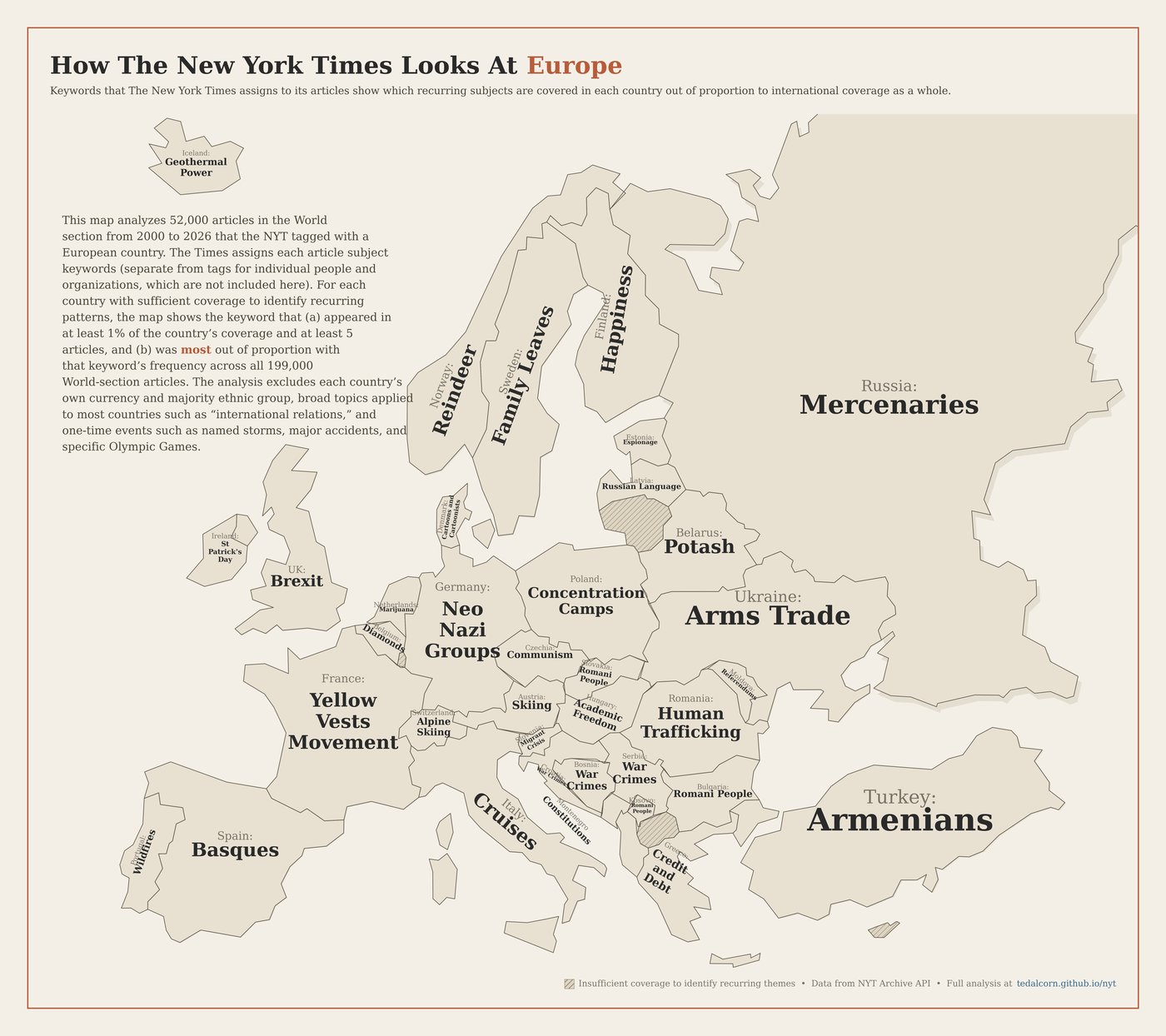
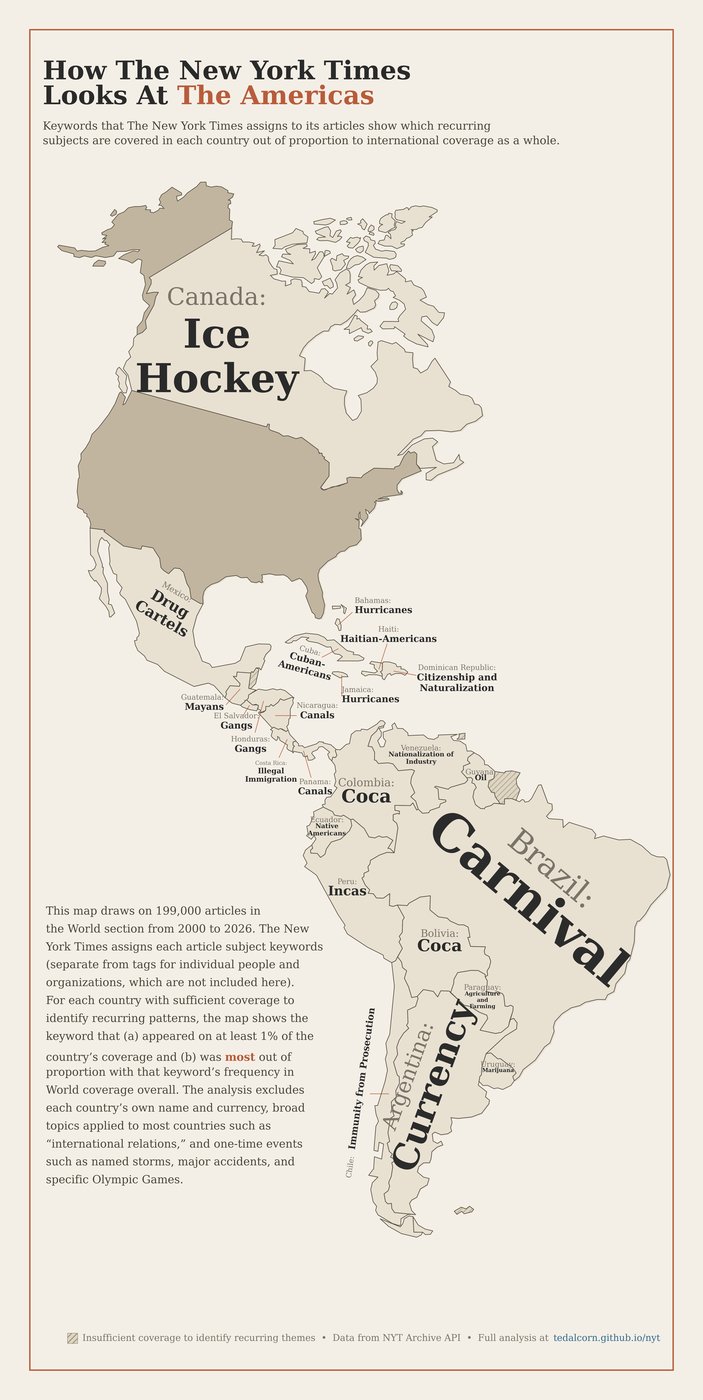
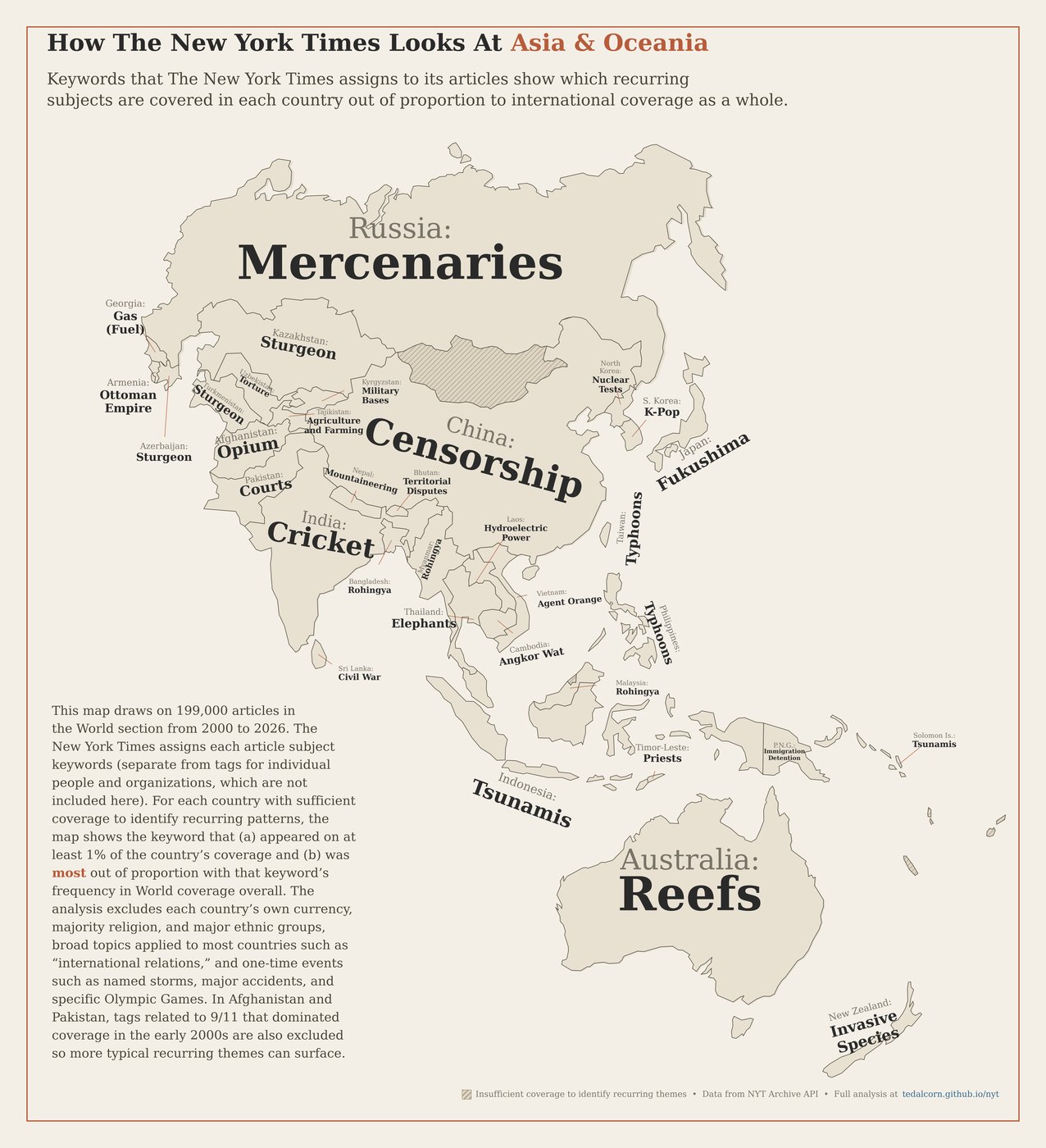
Analysis of international coverage draws from articles in the "World" section. Articles with geographic tags that appear in other sections (Opinion, Business, etc.) are not included.
Population data for per-capita calculations come from the 2020 U.S. Census. Country populations come from the Natural Earth 110m Cultural Vectors dataset (the POP_EST field, which aggregates UN and World Bank figures).
For each state and country, the popup lists the subjects that appear disproportionately in its coverage compared to the paper as a whole. Generic items every state or country has — election machinery (Elections, Senate, etc.), local-government roles (Mayors, Governors (US), District Attorneys), and broad inter-government tags (Federal-State Relations, International Relations) — are excluded, since their presence is more often driven by an occasional standout incident than by anything genuinely recurring. Standing-feature articles (correction digests, calendar listings, real-estate roundups, daily lottery numbers, Letters to the Editor, Metropolitan Diary, etc.) are also excluded from the score so they can't manufacture phony recurring topics. Each remaining tag is then scored by how much more frequently it appears in the state's or country's articles than in the corpus overall. The top ten by score are split into two columns. Headline events are subjects whose tag names refer to a specific dated incident — either a single year (Hurricane Sandy (2012), Newtown, Conn, Shooting (2012), Russian Invasion of Ukraine (2022)) or a multi-year war or crisis whose start year falls within the dataset's reporting period (Iraq War (2003-11), Afghanistan War (2001- ), Israel-Gaza War (2023- )). Recurring themes is everything else, capped at seven. The classification is based on tag-name structure rather than on when coverage clusters — a topic that became prominent in a single year (such as In Vitro Fertilization in 2024 after the Alabama Supreme Court ruling) is still a recurring theme, not a headline event. Conversely, historical eras whose tag-name year range ends well before our coverage period (World War II (1939-45), Civil Rights Movement (1954-68)) are recurring even if their tag carries dates, because the coverage is retrospective rather than event-driven.
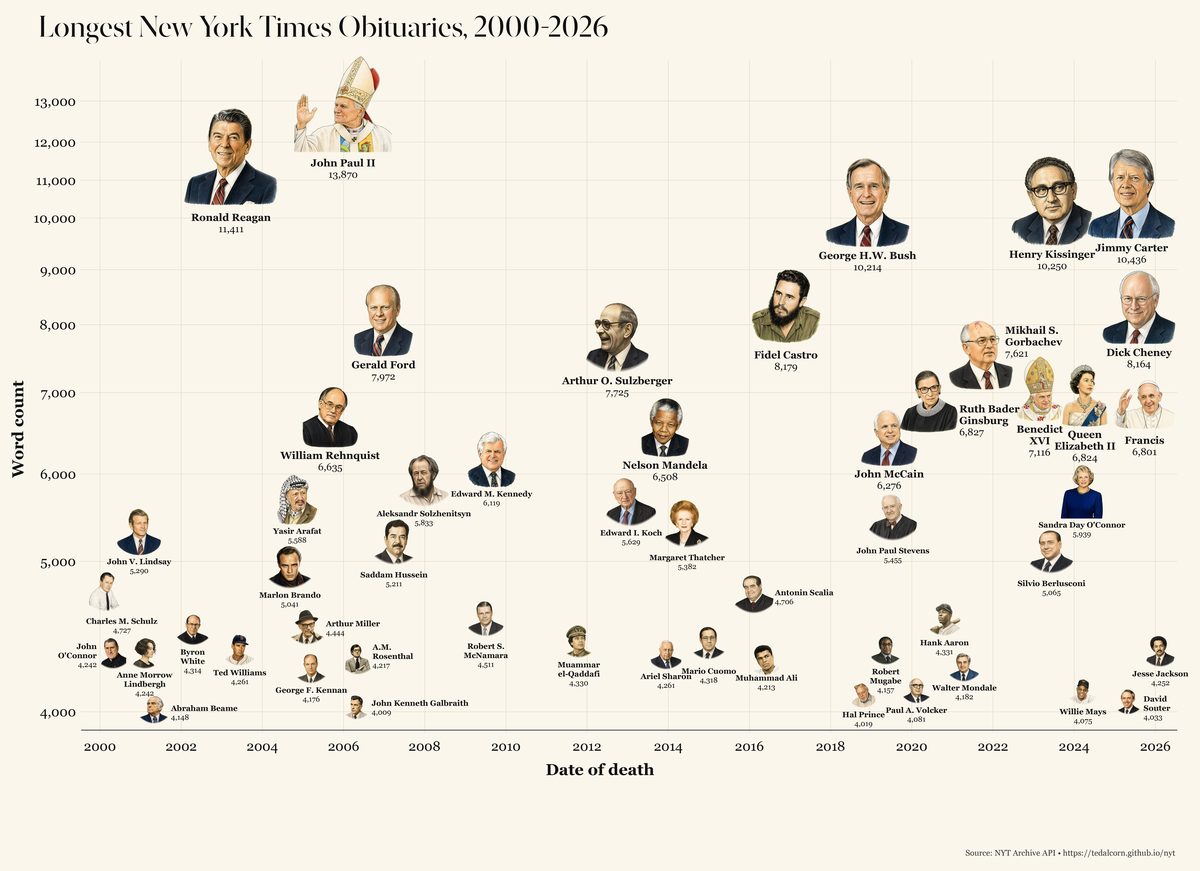
A number of steps were taken to identify all obituaries. Records were included if the API tagged them type_of_material as Obituary (in any of its variants), filed them under the Obits desk or Obituaries section, or assigned them to the 9/11 Portraits of Grief series. Year-end roundups, paid memorial notices, and multi-subject features were excluded.
Obituaries that appear to have run at distinct URLs within a few days of each other were then merged into a single canonical entry.
Each obituary was parsed for name, age, gender, and profession from the headline and abstract, relying on honorifics (Mr./Mrs./Sir/Dame) and pronouns (he/his vs. she/her) the paper used. Special series including Overlooked No More (retroactive obituaries for historically overlooked figures), historical obituaries republished for special occasions like Women's History Month, and the 9/11 Portraits of Grief feature were also tagged.
The Portraits of Grief series ran from September 2001 through 2002 and ultimately included roughly 1,910 individual portraits of 9/11 victims. Only ~400 are individually URL-addressable in the Archive API; the remainder were either bundled into daily compilation articles or are not separately indexed, so this dashboard surfaces only the subset the API exposes as standalone records.
The Times publishes a digest of its corrections each day at a stable URL under pageoneplus, and this dashboard scrapes every such digest the Archive API has tagged as a Correction since 2014. Each individual correction blurb is pulled out of the digest page, and where the correction itself links to the article it concerns, that link is followed; otherwise the matcher uses topic-keyword overlap and the correction's date phrase to find the most likely article within a few days of when it ran. About 99 percent of the roughly 17,700 corrections in the dataset are linked back to a specific article.
Each correction is also tagged with a few quality signals. The day of the week the correction cites ("An article on Friday about…") is converted into a likely print date and compared to the matched article's online pub date, which lets the dashboard flag matches where the two dates disagree by more than a few days. The word count of the correction blurb itself is recorded as a way to spot truncated or unusually long entries. These flags surface candidates for manual review and feed back into the matching pipeline.
The per-100-articles view divides correction counts by the total number of articles published by that section or reporter in the same year, drawn from the same Archive API used elsewhere on this dashboard.
Known quirks in the Archive API data, in chronological order. Where this dashboard applies a correction, it's noted explicitly.
section_name = "Science". By 2005, the same desk's output was being filed as "Health" (411 articles), "Opinion" (331), or left untagged, with only 102 still tagged "Science". A new "Health" section was being broken out at this point. The dashboard shows the unedited tag.section_name = "Arts", producing a sharp 2008–2010 spike of sub-200-word entries (40% in 2009 vs. ~10% in adjacent years). Most are short blog posts linking out to other coverage. Same root cause as the 2009 blog-labeling shift, with a wider time window for Arts specifically.People and organizations drawn from NYT keyword metadata. Subject tags (e.g. immigration) are surfaced in the Beats tab. Check names to compare coverage over time; click a name to see details.
Loading subjects data…
Search NYT subject tags to find which journalists cover a topic. Tags are drawn from the NYT's own metadata.
Recurring columns and special coverage that span sections or don't fit neatly into the section taxonomy.
Draws on geographic tags from NYT metadata exclusively in articles from the "World" section. Tagging coverage appears to have been less consistent in 2000–2003.
Draws on geographic tags from NYT metadata in the "U.S." section and, optionally, "New York" section to encompass local coverage.
Every Times obituary since 2001, with name, age, gender, and role parsed from the API.
Every correction the Times printed since 2017, linked to the underlying article.
| to search for multiple terms in one line (e.g. iraq | iran)